The Large Impact of MPI Collective Algorithms on AWS EC2 HPC cluster
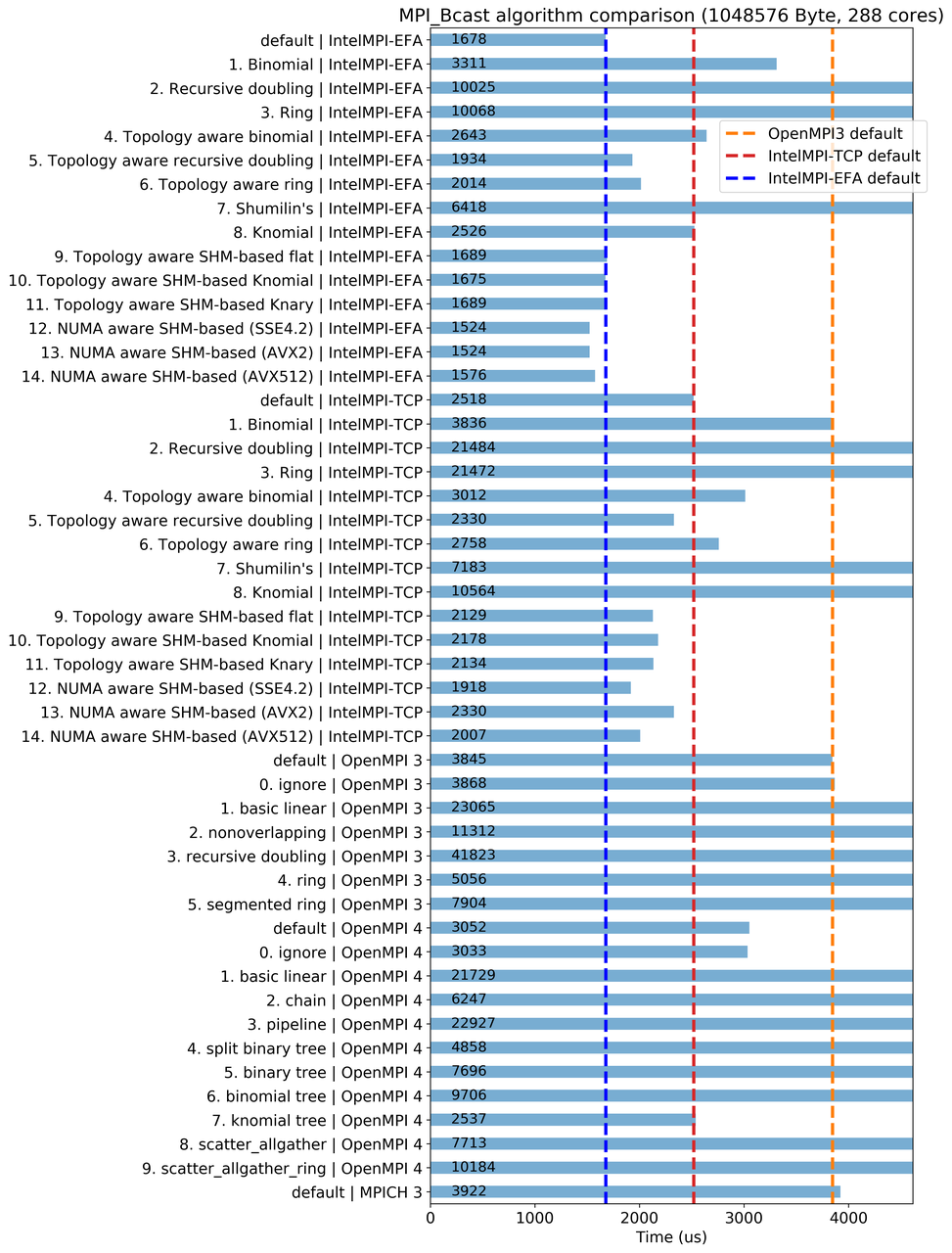
I recently found that, on an EC2 HPC cluster, OpenMPI collectives like MPI_Bcast and MPI_Allreduce are 3~5 times slower than Intel-MPI, due to their underlying collective algorithms. This problem is reported in detail at https://github.com/aws/aws-parallelcluster/issues/1436. The take-away is that one should using Intel-MPI instead of OpenMPI to get optimal performance on EC2. The performance of MPI_Bcast is critical for I/O-intensive applications that need to broadcast data from master to the rest of processes.
It is also possible to fine-tune OpenMPI to narrow the performance gap. For MPI_Bcast, the "knormial tree" algorithm in OpenMPI4 can give 2~3x speed-up over the out-of-box OpenMPI3/OpenMPI4, getting closer to Intel-MPI without EFA. The algorithm can be selected by:
orterun --mca coll_tuned_use_dynamic_rules 1 --mca coll_tuned_bcast_algorithm 7 your_mpi_program
Here are the complete code and instructions to benchmark all algorithms: https://github.com/JiaweiZhuang/aws-mpi-benchmark
Below is a comparison of all available MPI_Bcast algorithms (more in the GitHub issue). The x-axis is clipped to not show very slow algorithms. See the numbers on each bar for the actual time.
Comments
Comments powered by Disqus